对于新项目,我们建议您使用新的 Kinesis Data Analytics 工作室,而不是 SQL 应用程序的 Kinesis Data Analytics。Kinesis Data Analytics Studio 将易用性与高级分析功能相结合,使您能够在几分钟内构建复杂的流处理应用程序。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
示例:检索最常出现的值 (TOP_K_ITEMS_TUMBLING)
这个 Amazon Kinesis Data Analytics 示例演示了如何使用该TOP_K_ITEMS_TUMBLING函数在翻滚窗口中检索最常出现的值。有关更多信息,请参阅 Amazon Kinesis Data Analytics SQL 参考中的TOP_K_ITEMS_TUMBLING函数。
在对数万或数十万个密钥进行聚合时,如果您希望降低资源占用,则 TOP_K_ITEMS_TUMBLING 函数很有用。该函数生成的结果与使用 GROUP BY 和 ORDER BY 子句进行聚合一样。
在此示例中,您将以下记录写入 Amazon Kinesis 数据流:
{"TICKER": "TBV"} {"TICKER": "INTC"} {"TICKER": "MSFT"} {"TICKER": "AMZN"} ...
然后,您将 Kinesis Data Analytics 应用程序Amazon Web Services Management Console,将 Kinesis Data Analytics 应用程序。发现过程读取流式传输源上的示例记录,并推断出具有一个列 (TICKER) 的应用程序内部架构,如下所示:
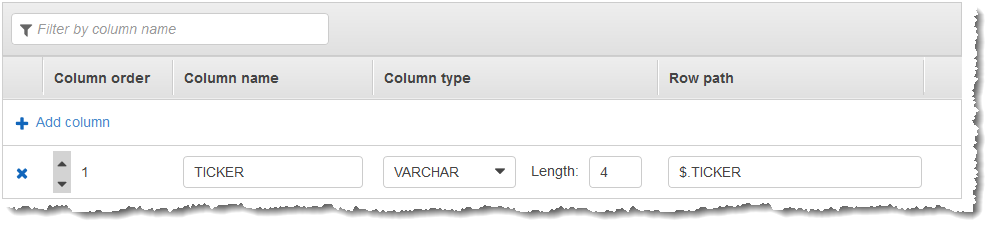
您使用应用程序代码以及 TOP_K_VALUES_TUMBLING 函数以创建数据的窗口式聚合。然后,将结果数据插入另一个应用程序内部流,如下面的屏幕截图所示:
在以下步骤中,您将创建一个 Kinesis Data Analytics 应用程序,该应用程序检索输入流中最常出现的值。
步骤 1:创建 Kinesis Data 流
创建 Amazon Kinesis 数据流并按如下方式填充记录:
登录到 Amazon Web Services Management Console,然后通过以下网址打开 Kinesis 控制台:https://console.aws.amazon.com/kinesisvideo/home
。 -
在导航窗格中,选择 Data Streams (数据流)。
-
选择 Create Kinesis stream (创建 Kinesis 流),然后创建具有一个分片的流。有关更多信息,请参阅 Amamamamazon Kinesis Dat a Streams 开发人员指南中的创建流。
-
要在生产环境中将记录写入到 Kinesis 数据流,我们建议您使用 Kinesis 客户端库或 Kinesis 数据流 API。为简单起见,此示例使用以下 Python 脚本以便生成记录。运行此代码以填充示例股票代码记录。这段简单代码不断地将随机的股票代码记录写入到流中。让脚本保持运行,以便可以在后面的步骤中生成应用程序架构。
import datetime import json import random import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return { 'EVENT_TIME': datetime.datetime.now().isoformat(), 'TICKER': random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']), 'PRICE': round(random.random() * 100, 2)} def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey") if __name__ == '__main__': generate(STREAM_NAME, boto3.client('kinesis'))
步骤 2:创建 Kinesis Data Analytics 应用程序
创建 Sis Data Analytics 应用程序,如下所示:
打开 Kinesis Data Analytics 控制台,网址为 https://console.aws.amazon.com/kinesisanalytics
。 -
选择 Create application (创建应用程序),键入应用程序名称,然后选择 Create application (创建应用程序)。
-
在应用程序详细信息页面上,选择 Connect streaming data (连接流数据),以连接到源。
-
在 Connect to source (连接到源) 页面上,执行以下操作:
-
选择在上一部分中创建的流。
-
选择 Discover Schema (发现架构)。等待控制台显示推断的架构和为创建的应用程序内部流推断架构所使用的示例记录。推断的架构包含一列。
-
选择 Save schema and update stream samples。在控制台保存架构后,选择 Exit (退出)。
-
选择 Save and continue。
-
-
在应用程序详细信息页面上,选择 Go to SQL editor (转到 SQL编辑器)。要启动应用程序,请在显示的对话框中选择 Yes, start application (是,启动应用程序)。
-
在 SQL 编辑器中编写应用程序代码并确认结果如下所示:
-
复制下面的应用程序代码并将其粘贴到编辑器中:
CREATE OR REPLACE STREAM DESTINATION_SQL_STREAM ( "TICKER" VARCHAR(4), "MOST_FREQUENT_VALUES" BIGINT ); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM * FROM TABLE (TOP_K_ITEMS_TUMBLING( CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM_001"), 'TICKER', -- name of column in single quotes 5, -- number of the most frequently occurring values 60 -- tumbling window size in seconds ) ); -
选择 Save and run SQL。
在 Real-time analytics (实时分析) 选项卡上,可以查看应用程序已创建的所有应用程序内部流并验证数据。
-